本記事は『コピペで簡単実行!キテレツおもしろ自然言語処理 PythonとColaboratoryで身につく基礎の基礎』の「第5章 「??」-「群馬」=「宇都宮」-「栃木」を機械に求めさせる」を抜粋したものです。掲載にあたって一部を編集しています。
「??」-「群馬」=「宇都宮」-「栃木」を機械に求めさせる
「グンマー」
あなたも一度は聞いたことがあると思います。北関東の最奥にある伝説の魔境、海のない陸の孤島、「生きて帰ったものはいない」と言われる未開の地のことです。
え、あなたの知っている「群馬」と違うですって? 異世界から転生されてきた方でしょうか? 最近よく見かけるんですよね、そういう方々。以下のスマホアプリを遊ぶとこの世界のグンマーのことをよく理解できると思うのでオススメです。ぜひ検索してみてください。
- 「群馬ファンタジー TRPG」伝説の群馬県からの脱出を目指すダークファンタジーTRPG
- 「ぐんまのやぼう」日本を全て制圧して群馬帝国を作るシミュレーションゲーム

さて、異世界から来て優秀なチートスキルを持つあなた様ならば、このようにアプリで遊びながら容易にグンマーを理解できます。しかしコンピュータに群馬のことを知ってもらうにはどうすればよいのでしょうか? 「形態素解析」では「群馬県」「栃木県」「埼玉県」「神奈川県」は全て同じ扱いです。
人間が自然言語を操るときには、その高度な背景知識によって各単語にそれぞれの「イメージ」を持っています。「北海道」であれば大きいとか寒いとか海鮮とか……。「北海道」のように大きい、広い、などと会話すれば自然ですが、「埼玉」のように大きい、広い、と話すと異世界転生者だとバレてしまうかもしれません。
本章では、コンピュータが「群馬」の意味をどう理解しているのかを知って、以下の計算を機械に解かせてみたいと思います。
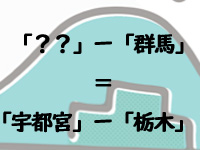
「??」-「群馬」=「宇都宮」-「栃木」
深淵なるグンマーを「覗く」恐ろしいクイズです。グンマーを覗くとき、グンマーもまた栃木を覗いているのだ。異世界の小学生ならば「??」に入るのは「前橋」と答えてくれる気がします。ただし、新幹線の駅を持つ自分たちの町こそがグンマーの中心と思っている「高崎」の小学生以外に限ります。
小学生にもわかる問題といえど、コンピュータにこの問題が答えられるのでしょうか? コンピュータにとっては「群馬」と「インド」ですら区別することは至難のワザです。文法的にはどちらも「地名」という程度の分類にしかなりません。ましてや「群馬」と「栃木」は、時に人間ですら東西の位置を間違えてしまうようなライバル同士なのです。
これから作るのは、コンピュータがこのような「イメージ」や「意味」を扱うことができる革命的な方法です。
Word2Vecとは?
結論から申し上げますと、コンピュータ上で単語の意味を扱う場合には、単語(Word)をベクトルとして扱う方法が一般的です。「Word2Vec」といいます。

機械学習によって大量の文章を読み込ませ、近い意味の単語は近い座標になるように数値としてプロットします。図では平面ですが実際は50~300次元ほどの空間が使われます。意味を上手にプロットできると、お互いの位置関係から以下のようなベクトルの計算ができるのです。

「あー、単語をベクトルとして扱うってことね、完全に理解した!」という方も、「ちょっと難しいな」という方も、とりあえず動かしながら、この仕組みを見ていきましょう。
学習済みモデルの入手
機械学習において、入力値を受け取り、何かの計算や評価をして、出力値を出すモノのことを「モデル」と呼びます。「お手!」と言ったら手を出すように犬を訓練するのと同じで、入力値に対してどう出力すればよいのか「学習」を繰り返すことで、モデルの精度を上げることができます。
さて、人間によっては「カレー」が「飲み物」に分類されることがあるようですね。同様に、各単語の数値はモデルごとに大きく異なり、どのような文章をどのように学習させたか、に左右されます。
本章では既に機械学習を完了させている、作成済みの「Word2Vecの学習済みモデル」をダウンロードしてきて、まずその使い方を見ることにします。
まずColaboratoryで新しいノートブックを作成し、お使いのGoogle Driveをマウントしてください(Google Driveマウントの詳細な方法は書籍の第1章で解説しています)。
from google.colab import
drivedrive.mount('/content/drive')
次に以下のコマンドで、筆者が用意した学習済みモデルをダウンロードし(無料)、Google DriveにKITERETUというフォルダを作って保存します。
# KITERETUフォルダをマウントしたGoogle Driveフォルダ(MyDrive)内に作成する !mkdir -p /content/drive/MyDrive/KITERETU # Word2Vecの学習済みモデルをそのフォルダにダウンロードする(3ファイルで1セット:400MB弱ほど) !curl -o /content/drive/MyDrive/KITERETU/gw2v160.model https://storage.googleapis.com/nlp_youwht/w2v/gw2v160.model !curl -o /content/drive/MyDrive/KITERETU/gw2v160.model.trainables.syn1neg.npy https://storage.googleapis.com/nlp_youwht/w2v/gw2v160.model.trainables.syn1neg.npy !curl -o /content/drive/MyDrive/KITERETU/gw2v160.model.wv.vectors.npy https://storage.googleapis.com/nlp_youwht/w2v/gw2v160.model.wv.vectors.npy
上記のダウンロードコマンドを1回でも実行済みであれば、ダウンロードしたファイルは既にGoogle Drive内に保存されているため、Colaboratoryのセッションが切れたあとでも再実行不要です。
「群馬」に似ている単語は?
モデルファイルを読み込み、異界の地「群馬」と近い単語を眺めてみます。以下のコードを実行してください。
from gensim.models.word2vec import Word2Vec # 学習済みモデルのロード model_file_path = '/content/drive/MyDrive/KITERETU/gw2v160.model' model = Word2Vec.load(model_file_path) # モデル内に登録されている単語リストの長さをlen関数で見る(=単語数) print(len(model.wv.vocab.keys())) # 「群馬」に似ている単語TOP7を書き出す out = model.wv.most_similar(positive=[u'群馬'], topn=7) print(out)
293753
[('群馬県', 0.7760873436927795), ('栃木', 0.74561607837677), ('前橋', 0.7389767169952393), ('埼玉', 0.7216979265213013), ('高崎', 0.6891007423400879), ('伊勢崎', 0.6693984866142273), ('茨城', 0.6651454567909241)]
u'群馬'の冒頭のuは、この文字列がUTF-8で書かれていることを明言したもので、これを消しても基本的には同じ動作をします。また、ここではpositiveに群馬を入れていますね。群馬だから能天気でポジティブというわけではなく、ここでは単純に「プラス」として扱うという程度の意味です。あとでnegativeも出てきます。
今回ダウンロードしてきたモデルには、約29万語ほどの単語が登録されており、そのうち「群馬」に近いものは「群馬県」「栃木」「前橋」「埼玉」「高崎」「伊勢崎」「茨城」などであった、という結果になります。
「群馬」という単語が使われている文章をいろいろ想像してみてください。その「群馬」の箇所を何かの単語で差し替えることにします。29万語のうち、意味上の変化が最も少ない単語TOP7がこの7つであった、ということです。後ろの数字はその類似度を示しており、1.0を最大としてどれくらい似ているかを示しています。
この学習モデルはWikipediaのデータを学習させて作ったモデルです。私の世界のグンマーとは違う、まだセカンドインパクトが起きていない並行世界のデータのようですね。
「??」−「群馬」=「宇都宮」−「栃木」
単語の意味を「矢印」=「ベクトル」で表現できるととても嬉しいことが1つあります。それは「ベクトル同士は足し算や引き算ができる」 ということです。
さきほどは「群馬」や「カレー」などの1つの単語に対して、それに近い意味を持つ単語を出しましたが、意味を足し算・引き算した結果に対して近い意味を持つ単語を出すこともできるのです! いよいよ、以下の「??」に当てはまるものを機械に聞いてみましょう。
「??」-「群馬」=「宇都宮」-「栃木」
この式は、超高等数学テクニックを駆使すると、以下に変形できますね。
「??」=「宇都宮」-「栃木」+「群馬」
この式の右辺を元に、さきほどの.wv.most_similarの引数として、positiveにプラスとする単語、negativeにマイナスとする単語を入れるだけで、「ベクトル同士の足し算・引き算の結果に最も似ている単語」を出力してくれます。
out = model.wv.most_similar(positive=[u'宇都宮', u'群馬'], negative=[u'栃木'], topn=7) print(out)
[('前橋', 0.7003206014633179), ('高崎', 0.6781094074249268), ('上野', 0.6506083607673645), ('伊勢崎', 0.6436746120452881), ('館林', 0.6416027545928955), ('群馬県', 0.5982699990272522), ('川越', 0.5848405361175537)]
さあ、見事「前橋」が最も似ていると出てきました。高崎市民の皆様は残念でしたね。また、「上野」が出ている理由はおそらく、動物園のある東京の「上野」が前橋と近いわけではなくて、群馬の旧国名の「上野国(こうずけのくに)」が原因です。
「上野」という単語と「群馬」との関係性が高いと評価されたのでしょう。「伊勢崎」や「館林」も群馬の地名ですが、「川越」は埼玉なのでこちらは誤解されていますね。



